Introduction
Building autonomous agents for specialized industries starts with choosing the right foundation model, the core engine behind the entire system. Before we can develop advanced agents for domains like private market funding, we need a clear understanding of what foundation models are available today.
This article presents our taxonomy of the foundation model landscape, with particular focus on Domain-Specific Foundation Models (DSFMs): what they are, how to classify them, and why they matter for funding applications.
Part 1: What Makes a Model "Domain-Specific"?
Stanford's Center for Research on Foundation Models defines foundation models as large-scale models that are generalizable, adaptable, and scalable, and that can be reused across a wide range of downstream tasks.
General-purpose models like GPTs or Claude embody this definition broadly; they are polymaths capable of drafting legal contracts, debugging code, and explaining quantum mechanics. But a new class is emerging: models tailored for specific verticals.
Our working definition
A Domain-Specific Foundation Model (DSFM) is a foundation model tailored—through data, architecture, or training strategy—to perform well across many tasks within a particular domain.
The key phrase is "many tasks." A model fine-tuned to solve one specific equation is narrow, not foundational. A model fine-tuned on financial data that can handle forecasting, risk assessment, and ledger interpretation retains the essential trait of adaptability; it is a DSFM.
The methodology question
Researchers often debate what qualifies as "domain-specific." The confusion stems from conflating three classification axes:
| Axis | Question |
|---|---|
| Data-Centric | Was it trained on domain-specific corpora (medical texts, financial filings)? |
| Modality-Centric | Does it specialize in a particular input type (text, vision, time-series)? |
| Methodology-Centric | Was it pre-trained from scratch or fine-tuned from a general model? |
Our position: methodology is secondary to outcome. A general model heavily fine-tuned on domain data counts as a DSFM, provided it retains adaptability across multiple downstream tasks. What matters is how the model behaves, not the ideological purity of its training pipeline.
Part 2: A Taxonomy of Foundation Models
We organize the landscape into three layers:
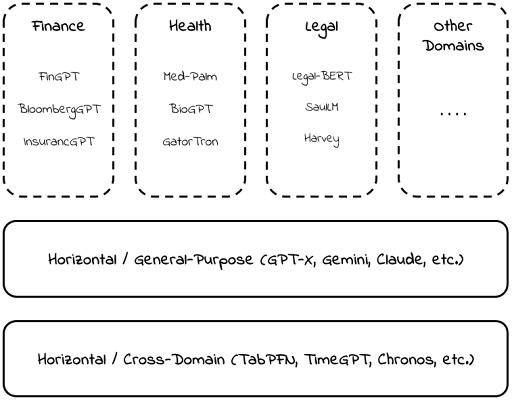
General-Purpose Models
The broad foundation: GPTs, Claude, Gemini, and LLaMA. These handle virtually any task but lack deep domain expertise.
Cross-Domain Methodological Models
These specialize in a problem type or data modality rather than an industry vertical.
- TimeGPT: foundation model for time-series forecasting, applicable wherever temporal data exists.
- TabPFN: foundation model for tabular classification.
These are horizontal building blocks, not general-purpose, but not vertical either. They can be composed into domain-specific solutions.
Vertical (Domain-Specific) Models
Models tailored to particular industries: healthcare, legal, and finance. Examples include Med-PaLM (medical reasoning), Harvey (legal), and various financial fine-tunes.
Part 3: Application to Funding
Our primary interest is the domain of monetary transactions, and in particular, funding transactions, where value flows from cash into a business. Our domain has distinctive characteristics that constrain model selection:
| Characteristic | Implication |
|---|---|
| Tabular-heavy data | Requires models designed for rows and columns (TabPFN, TabTransformer), not just sequences |
| Temporal dynamics | Payment histories, application cycles, and default trends demand sequential modeling |
| Structured decisions | Favors interpretable architectures over open-ended generative models |
| Heterogeneous inputs | Must handle numerical, categorical, and unstructured text together |
Relevant Architectures
Navigating the funding domain requires handling lost-in-the-middle effects, temporal cycles, and messy inputs. These constraints dictate our choice between symbolic models (agnostic to column labels; purely statistical) and semantic models (sensitive to labels; relying on world knowledge).
This distinction raises a fundamental question: is financial prediction better served by isolated numerical analysis or broad conceptual understanding? To answer this, we evaluate three model families that satisfy our strict criteria for interpretability, zero-shot performance, and covariate handling.
1) Tabular Foundation Models
Taxonomy: Cross-Domain Methodological | Processing: Symbolic | Examples: TabPFN
Standard sequential LLMs often struggle with the inherent grid structure of financial data, losing critical row-column relationships in the text stream. Tabular foundation models address this by focusing on the format (tables) rather than the content (finance).
Leading this class is TabPFN, a transformer pre-trained once on over 100 million synthetic tasks. Unlike deep learning models that require weight updates for every new dataset, TabPFN leverages in-context learning to autonomously discover efficient algorithms during inference. It achieves this via a dual-attention mechanism: Feature Attention (horizontal) processes within-row relationships (for example, inside a single loan application), while Sample Attention (vertical) processes cross-sample patterns across historical data.
This architecture allows the model to remain invariant to input order while predicting full probability distributions, including complex bimodal outcomes, in a single forward pass. For funding agents, this capability provides the uncertainty quantification required for high-stakes risk assessment, a critical advantage over simple point predictions.
2) Time-Series Foundation Models
Taxonomy: Cross-Domain Methodological | Processing: Symbolic | Examples: TimeGPT-1, TimesFM
Funding transactions are inherently temporal; a business's value is rarely determined by a static snapshot and is instead shaped by the trajectory of historical cash flows and the volatility of payment cycles. Time-series foundation models (TSFMs) are designed to bridge the gap between numerical sequence modeling and strategic financial reasoning.
Models like Google's TimesFM and Nixtla's TimeGPT-1 pioneered zero-shot forecasting, allowing accurate predictions on new data without additional training. TimesFM uses a streamlined architecture that processes data in small chunks and predicts long-term trends in multi-step patches. Forecasting larger blocks simultaneously reduces cumulative error that typically appears in point-by-point predictions. TimeGPT-1 was trained on roughly 100 billion data points, enabling cross-industry pattern transfer and high-quality instant forecasts through a single inference pass.
Modern financial agents require more than point forecasts; they must estimate the probability of catastrophic events like default. Advanced 2026-era architectures such as Moirai-2 and Chronos-2 prioritize risk-aware forecasting by producing probabilistic outputs rather than single values. By integrating quantile-oriented objectives or conformal prediction frameworks, these models produce prediction intervals with explicit coverage targets. This enables multi-step probabilistic forecasts for questions like: what is the 90th percentile risk of a missed payment in Week 8? Because they are pre-trained on large time-series corpora, they also support zero-shot inference on new payment ledgers.
3) Fine-Tuned General-Purpose Models
Taxonomy: General-Purpose Models (adapted via fine-tuning) | Processing: Semantic
This class starts from strong general-purpose LLMs and compares behavior across three regimes: out-of-the-box use, light prompt guidance, and full fine-tuning. Even without specialized training, modern LLMs can reason over cash-flow narratives, summarize financial signals, and surface obvious risk patterns through broad world knowledge.
Adding minimal structure through prompts or schemas often yields substantial gains through in-context learning alone. Fine-tuning on domain-specific data, such as transactions, underwriting notes, and funding outcomes, can further improve consistency, terminology alignment, and calibration while preserving cross-task flexibility. For our goals, comparing these regimes clarifies when semantic reasoning is sufficient, when domain data materially improves performance, and whether fine-tuning justifies its added operational complexity.
What's next?
Having identified the three primary architectural families, our next step is to enter the laboratory. We will define a fair experimental arena tiered across zero-shot baselines, individual dataset fine-tuning, and a unified model tuned on domain knowledge.
We will also detail our data strategy, including how we curate diverse datasets to represent specific funding tasks, from high-stakes risk assessment (tabular track) to temporal cash-flow dynamics (time-series track). Finally, we will show how this setup addresses the "Math" problem (reliable reasoning and numerical accuracy) and the "Haystack" problem (surfacing relevant signal amid noisy data) to identify the most cost-effective path to state-of-the-art outcomes.