In our previous post, we established the Experimental Arena, a weighted leaderboard that revealed a performance gap between Symbolic specialists like TabPFN and Semantic generalists like GPT-4o-mini. However, those results were based on a full-feature environment where models had access to every available data column.
In this post, we move from raw performance to data efficiency. We address the "Haystack Problem": high-dimensional datasets packed with potential signals but often drowned in noise. By integrating an XGBoost-based feature selection guard, we test whether reducing information can help models focus, while simultaneously lowering the computational and financial costs.
Filtering for Significance
High-dimensional datasets, such as the World Development Indicators (WDI) with its 454 features, present a significant hurdle for any model. Processing hundreds of columns increases the risk of overfitting and significantly raises the token usage, and therefore the cost, required for LLMs.
To mitigate this, we implemented a feature selector using XGBoost. This selector prunes the dataset down to its most significant features before the data ever reaches the model. The effectiveness of this approach depends on the threshold used to discard features, a hyperparameter that determines how much information is sacrificed. We set these thresholds manually by analyzing the resulting drop in performance across various feature counts. By identifying the point where the performance drop was most pronounced, we were able to preserve critical financial signals while stripping away computational noise.
For our laboratory, we employed human-in-the-loop selection:
- Focusing on Impact: We identified which specific data columns had the most significant influence on the final prediction and prioritized those.
- The Strategic Balance: This allowed us to find the "sweet spot" where we could cut computational costs without losing the vital signals that drive funding decisions.
Quantifying Information Preservation vs. Loss
We also measure the compression rate: how much information is lost in the process in total. Our analysis reveals an aggressive pruning strategy across our setup. Our XGBoost-based feature selector retained only 36% of the original features. This means nearly two out of every three columns were discarded.
| Dataset Name | Original Columns | Reduced Columns | Percentage Reduction |
|---|---|---|---|
| Home Credit Default Risk | 491 | 117 | 76.20% |
| World Dev. Indicators (WDI) | 454 | 50 | 89.00% |
| Prosper Loan | 61 | 8 | 86.90% |
| Econ Incentives | 59 | 11 | 81.40% |
| PUBD (Note Rates) | 54 | 16 | 70.40% |
| MTA Daily Ridership | 32 | 14 | 56.20% |
| Walmart Sales | 32 | 14 | 56.20% |
| Credit Card Fraud | 30 | 17 | 43.30% |
| Lending Club Loan | 25 | 9 | 64.00% |
| Loan Approval | 11 | 4 | 63.60% |
| Give Me Some Credit | 10 | 9 | 10.00% |
Table 1: Feature selection compression by dataset.
Here are some insights from the pruning process:
- Aggressive Compression: In the largest datasets, the reduction was harsh. For WDI, only 11% (50 out of 454) of features were kept. Prosper Loan saw a similarly high discard rate, retaining only 13.1%.
- Targeted Retention: Conversely, datasets that were already lean, like Give Me Some Credit, retained 90% of their features, suggesting the selector recognized the existing density of information.
- Task-Specific Logic: Regression datasets saw heavier pruning (averaging 28.4% retention) compared to Classification datasets (46.4%), indicating that regression tasks often harbor more numerical redundancy.
The Results: Signal vs. Noise
We re-evaluated our top-performing models using the reduced versions of the datasets. To interpret the resulting performance shifts, it is important to remember that our Regression WBS is a relative metric. For each dataset, scores are normalized between the best-performing model (1.0) and the worst-performing model (0.0). Because of this normalization, Regression WBS is insensitive to the absolute scale of prediction errors as long as the best and worst boundaries remain unchanged. Instead, the metric highlights relative movement within the leaderboard. This makes it easier to observe the performance differences.
One notable exclusion from this process is TimesFM. Unlike our tabular models that process data as independent rows of features, TimesFM operates as a univariate forecaster that consumes only the sequence of historical target values to predict future ones. Because its current architectural setup does not utilize a grid of independent feature columns, the concept of feature selection is inapplicable.
| Task Type | Model Name | Baseline WBS | w/ Feature Selection WBS | Change (%) |
|---|---|---|---|---|
| Classification | TabPFN | 0.819 | 0.811 | -0.98 |
| Classification | GPT-4o-mini fine-tuned | 0.806 | 0.797 | -1.12 |
| Regression | TabPFN | 0.777 | 0.716 | -7.85 |
| Regression | GPT-4o-mini fine-tuned | 0.284 | 0.621 | 118.66* |
Table 2: Feature selection impact. *Excludes Econ Incentives for a fair comparison with TabPFN (which faced context limits); its inclusion would result in a 144.01% mean change.
*The Regression Track
GPT-4o-mini showed a notable performance increase after feature selection, with the most significant gains occurring in datasets with a large number of features, though our results suggest this benefit is highly context-dependent. This trend points to a potential limitation of general-purpose LLMs when applied to high-dimensional numerical datasets. Because LLMs process numbers as fragmented text tokens rather than native numerical values, large tabular inputs can introduce substantial token-level noise that complicates mathematical reasoning.
By removing irrelevant features, such as the 404 columns pruned from the World Development Indicators (WDI) dataset, we effectively reduced the input space, which in several cases appeared to improve the model's ability to focus on meaningful signals. Additionally, the Econ Incentives dataset was omitted from our initial baseline reporting for TabPFN because its original data structure did not fully fit TabPFN's context window constraints prior to the feature selection process. However, this boost was not observed uniformly across all datasets. As we will explore in the following statistical analysis, the high degree of variance in these results suggests that while pruning can mitigate numerical distraction in specific high-noise environments, it is not yet a guaranteed fix for regression accuracy.
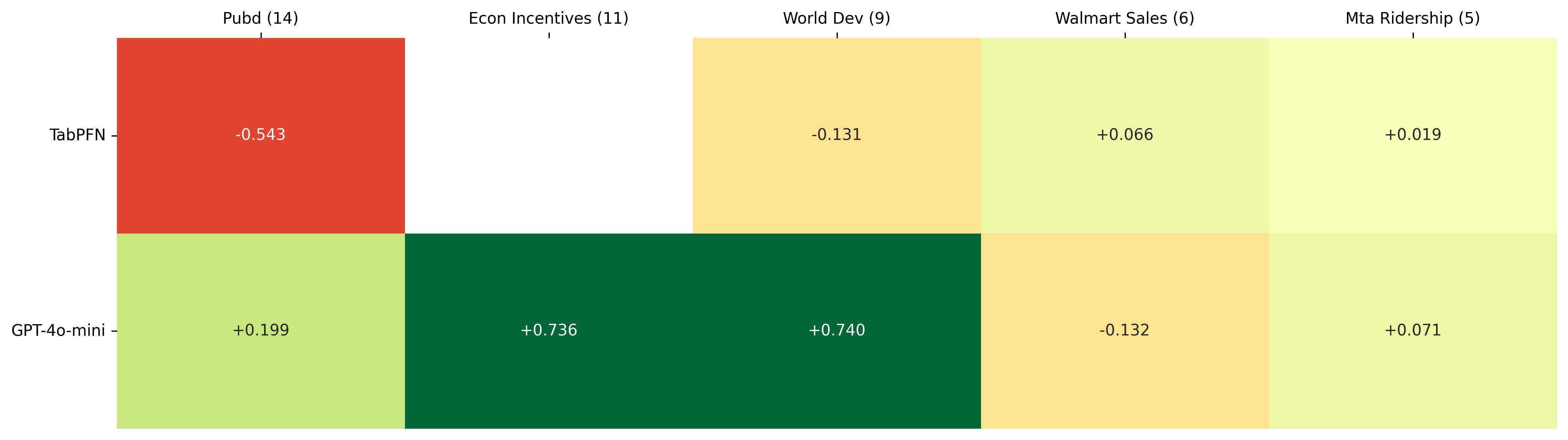
Figure 1: Feature selection impact on the regression results per dataset.
Note on Metrics: Unlike the classification results, marginal gains are used instead of percentages to maintain a consistent scale and avoid the distortion caused by near-zero baselines. In these regression tasks, where scores are normalized between 0 and 1, absolute differences provide a more direct measure of improvement toward the upper bound.
The Classification Track
While the general-purpose models improved with reduced feature sets, our tabular specialist, TabPFN, experienced a slight performance decrease (from 0.819 to 0.811). Unlike general-purpose LLMs, TabPFN is pretrained to perform in-context inference over tabular datasets and can exploit subtle interactions across features. By manually pruning the feature space, we likely removed weak but informative signals that the model could have incorporated into its predictive structure. This result suggests that for specialized tabular architectures, a richer feature context can sometimes improve performance, even when many features appear individually irrelevant.

Figure 2: Feature selection impact on the classification results per dataset.
Variance Analysis
To verify if the performance gains observed in our benchmark were consistent or dataset-dependent, we conducted a variance analysis across our model laboratory. This analysis helps determine the reliability of feature selection as a preprocessing strategy. Variance analysis shows a distinction between task types. Classification performance is highly stable across all models, with variance 0.0002. In contrast, regression performance is more dataset-dependent, showing significantly higher variance (0.08-0.16).
| Model | Task | Mean Delta | Variance |
|---|---|---|---|
| TabPFN to TabPFN (feat-sel) | Classification | -0.006 | 0.0002 |
| GPT-4o-mini (ft) to GPT-4o-mini (ft+fs) | Classification | -0.009 | 0.0002 |
| TabPFN to TabPFN (feat-sel) | Regression | -0.147 | 0.0766 |
| GPT-4o-mini (ft) to GPT-4o-mini (ft+fs) | Regression | 0.323 | 0.1577 |
Table 3: Per-model score consistency. Values are calculated using simple (unweighted) results without dataset weights.
Summary of Findings
Based on the statistical analysis, we draw the following conclusions:
- Classification Stability: Feature selection had a negligible impact on classification tasks, with mean changes near zero (< 0.01) and significantly low variance. This suggests that both generalists and specialists are inherently capable of navigating feature noise in categorical contexts.
- Regression Volatility: GPT-4o-mini experienced a substantial performance increase in regression (0.323), though the high variance (0.158) indicates this boost is inconsistent and primarily driven by specific high-dimensional datasets where pruning removes significant noise.
Our observations indicate that feature selection should be treated as a targeted tactical choice rather than a mandatory preprocessing step.
- Use Feature Selection when: You are adapting a General-Purpose Model (LLM) for Regression tasks involving high-dimensional or noisy data. In these cases, reducing the "token noise" can help the model lock onto critical signals.
- Avoid Feature Selection when: Using a Symbolic Specialist like TabPFN, as these models are designed to thrive on the full feature grid and often suffer a performance penalty when data is removed.
Conclusion
Our findings suggest that the decision to prune data is a strategic choice centered on the Return on Investment (ROI) of technical complexity.
- The Case for Generalists: For models like GPT-4o-mini, feature selection serves as a vital tool for regression, particularly in high-dimensional environments. While the performance boost can vary depending on the dataset, pruning helps lower the Investment Factor by reducing token costs and accelerating fine-tuning cycles.
- The Case for Specialists: If top-tier precision in high-stakes classification is the goal, the investment in a Symbolic Specialist like TabPFN remains justified. Unlike generalists, these models utilize the full feature grid effectively, and removing data can actually result in a performance penalty.
Ultimately, a funding agent must balance operational viability with predictive accuracy. While TabPFN remains the champion, feature selection provides a viable path for general-purpose models to evolve into competitive "Vertical experts" without the overhead of massive feature engineering.